相关信息
索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。通过索引我们可以快速定位到目标数据的位置。
优点:
- 提高查询速度
- 降低数据库的 I/O 消耗
- 降低 CPU 消耗
- 提高数据的唯一性
- 保证数据的完整性
缺点:
- 占用磁盘空间
- 降低数据的写入和更新速度
索引类型
| 索引类型 | 描述 |
|---|---|
| 逻辑功能划分 | |
| 普通索引 | 这是最基本的索引,它没有任何限制。它的主要任务是加快对数据的访问速度。 |
| 唯一索引 | 与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。 |
| 主键索引 | 主键索引是一种特殊的唯一索引,不允许有空值。 |
| 全文索引 | 全文索引用于全文搜索,只有 CHAR、VARCHAR 和 TEXT 列才能被索引。 |
| 物理划分 | |
| 聚簇索引 | 聚集索引是按照数据存放的物理位置为顺序的,能提高多行检索的速度。 |
| 非聚簇索引 | 非聚簇索引是按照逻辑顺序(索引的顺序)存储的,与数据在磁盘上的存储无关。 |
| 字段个数划分 | |
| 单列索引 | 单列索引是基于单个列的值创建的索引。 |
| 组合索引 | 组合索引是基于多个列的值创建的索引。 |
按逻辑功能划分
普通索引
CREATE INDEX 索引名 ON 表名 (字段名);唯一索引
CREATE UNIQUE INDEX 索引名 ON 表名 (字段名);主键索引
ALTER TABLE 表名 ADD PRIMARY KEY (字段名);全文索引
CREATE FULLTEXT INDEX 索引名 ON 表名 (字段名);按物理划分
聚簇索引
聚簇索引的索引和数据存储在一起,索引的顺序和数据的物理存储顺序一致。在 MySQL 中的主键索引就是聚簇索引,索引和数据都存在同一个 .ibd 文件中。
聚簇索引优缺点
优点:
- 聚簇索引可以减少磁盘 I/O 操作,提高查询效率。查询到索引就找到了数据,不需要再次查询数据。
- 聚簇索引可以减少数据碎片,提高数据的存储效率。
缺点:
- 聚簇索引的维护代价较高,插入、删除、更新数据时需要维护索引。
- 聚簇索引的数据存储是有序的,如果插入数据是无序的,可能会导致数据存储不连续,增加了数据的存储空间。
非聚簇索引
非聚簇索引的索引和数据存储在不同的地方,索引的顺序和数据的物理存储顺序不一致。在 MySQL 中的普通索引就是非聚簇索引,索引和数据分别存在两个 .ibd 文件中。
非聚簇索引优缺点
优点:
- 非聚簇索引的维护代价较低,插入、删除、更新数据时只需要维护索引。
- 非聚簇索引的数据存储是无序的,插入数据时不会导致数据存储不连续,减少了数据的存储空间。
缺点:
- 非聚簇索引查询效率较低,查询到索引后还需要再次查询数据。
- 非聚簇索引会增加磁盘 I/O 操作,降低查询效率。
- 非聚簇索引会增加数据碎片,降低数据的存储效率。
- 非聚簇索引的数据存储是无序的,可能会导致数据存储不连续,增加了数据的存储空间。
覆盖索引
由于非聚簇索引和数据是分开存储的,意味着在使用索引搜索到数据后还需要回表查询数据,这样会增加一次 I/O 操作。为了减少 I/O 操作,可以使用覆盖索引。覆盖索引是指查询的字段都在索引中,不需要回表查询数据。
按字段个数划分
单列索引
CREATE INDEX 索引名 ON 表名 (字段名);组合索引
CREATE INDEX 索引名 ON 表名 (字段名1, 字段名2, ...);创建索引原则
- 最左前缀原则
MySQL 索引使用最左前缀原则,即在查询时只能使用索引的最左前缀列。例如,如果创建了一个组合索引 (a, b, c),那么查询时可以使用 (a)、(a, b)、(a, b, c) 三种索引,但不能使用 (b, c)、(c) 等索引。
注意
最左匹配原则在遇到 >=、<=、between、like 前缀匹配 时可以触发索引,但是如果遇到 > 和 < 则不会触发索引查询。
- 选择唯一性索引
在选择索引时,应该优先选择唯一性索引,因为唯一性索引可以保证数据的唯一性,避免数据重复。
- 选择区分度高的索引
在选择索引时,应该选择区分度高的索引,区分度高的索引可以减少扫描的数据量,提高查询效率。
- 选择索引列
在选择索引列时,应该选择查询频繁的列,避免选择不常用的列,提高索引的利用率。
推荐选择的字段
- 频繁查询的字段
- 频繁排序的字段
- 不为 NULL 的字段
- 经常用来 JOIN 的字段
- 尽量使用前缀索引
如果索引字段的长度较长,可以使用前缀索引,前缀索引可以减少索引的存储空间,提高索引的查询效率。
- 尽量扩展索引而不是新建索引
如果我们已经有一个 a 索引, 如果我们需要一个 a,b 索引,那么我们可以直接在 a索引上扩展 b 字段,而不是新建一个 a,b 索引。
- 索引数量不要太多
单表的索引数量不要太多,太多索引会增加数据的维护成本,降低数据写入效率。
索引下推
索引下推(Index Condition Pushdown)是 MySQL 5.6 引入的一个优化特性,可以减少回表查询数据,提高查询效率,主要用于组合索引。
工作原理
在没有索引下推之前,如果我们有一个组合索引 (a, b),查询条件是 a = 1 and b = 2,MySQL 会先使用索引 (a, b) 查询出所有 a = 1 的数据,然后再回表查询对应的完整数据行,接着再用 b = 2 的条件判断每一行是否满足条件,将满足条件的数据行返回。
有了索引下推之后,MySQL 会先使用索引 (a, b) 查询出所有 a = 1 and b = 2 的数据,然后再回表查询对应的完整数据行,减少了回表查询的数据量,提高了查询效率。
索引的数据结构
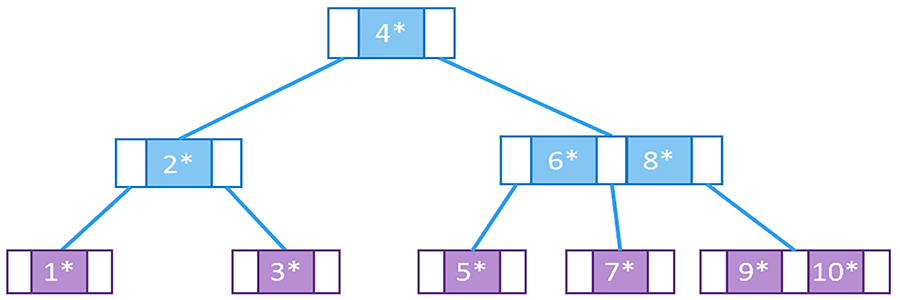
B 树
B 树是一种多路平衡查找树,是一种常用的索引数据结构。
B 树的特点:
- 每个节点都包含多个子节点,每个节点的子节点个数范围是
[m/2, m],其中m是 B 树的层数。 - 所有叶子节点都在同一层。
- 根节点至少有两个子节点,除非根节点是叶子节点
- 有
k个子节点的非叶子节点包含k-1个键值 - 每个节点都包含索引和全部数据
B+ 树
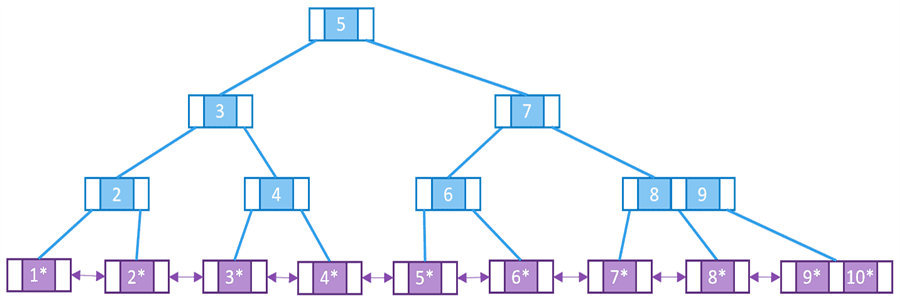
B+ 树是 B 树的一种变种,是一种常用的索引数据结构。和 B 树相比,B+ 树的叶子节点只包含索引,不包含数据,所有叶子节点都在同一层,叶子节点之间通过指针连接。由于节点只包含索引,在同样的块大小下,B+ 树可以存储更多的索引,减少了树的层数,提高了查询效率。由于叶子节点之间通过指针连接,可以支持范围查询,查询速度大大快于 B 树。
B+ 树的特点:
- 所有叶子节点都在同一层。
- 非叶子节点只包含索引,不包含数据。
- 叶子节点之间通过指针连接。
- 叶子节点包含全部数据。
- 同样数量的数据,B+ 树的高度比 B 树低。
B树和B+树的区别
| B-树 | B+ 树 | |
|---|---|---|
| 数据指针和键 | 所有内部节点和叶节点都包含数据指针和键 | 只有叶节点包含数据指针和键,内部节点只包含键 |
| 重复键 | 没有重复的键 | 存在重复的键,所有内部节点也存在于叶子中 |
| 叶节点链接 | 叶节点之间没有链接 | 叶节点之间相互链接 |
| 顺序访问 | 节点的顺序访问是不可能的, 范围查询需要中序遍历 | 所有节点都存在于叶子中,因此可以像链表一样进行顺序访问 |
| 搜索速度 | 搜索键的速度较慢 | 搜索速度更快 |
| 特定数量条目的高度 | 对于特定数量的条目,B 树的高度较大 | 对于相同数量的条目,B+ 树的高度小于 B-树 |