Info
An index is a data structure in a relational database that pre-sorts the values of one or more columns. Through the index, we can quickly locate the position of the target data.
Advantages:
- Improve query speed
- Reduce the I/O consumption of the database
- Reduce CPU consumption
- Improve data uniqueness
- Ensure data integrity
Disadvantages:
- Occupies disk space
- Reduces the speed of data writing and updating
Index Types
| Index Type | Description |
|---|---|
| Logical Function Division | |
| Ordinary Index | This is the most basic index, it has no restrictions. Its main task is to speed up access to data. |
| Unique Index | Similar to an ordinary index, the difference is: the value of the index column must be unique, but null values are allowed. If it is a composite index, the combination of column values must be unique. |
| Primary Key Index | The primary key index is a special unique index, null values are not allowed. |
| Full-text Index | Full-text index is used for full-text search, only CHAR, VARCHAR and TEXT columns can be indexed. |
| Physical Division | |
| Clustered Index | The clustered index is sorted according to the physical location of the data storage, which can improve the speed of multi-row retrieval. |
| Non-clustered Index | The non-clustered index is stored in logical order (the order of the index), which is unrelated to the storage of data on the disk. |
| Field Number Division | |
| Single Column Index | A single column index is an index created based on a single column value. |
| Composite Index | A composite index is an index created based on multiple column values. |
Logical Function Division
Ordinary Index
CREATE INDEX index_name ON table_name (field_name);Unique Index
CREATE UNIQUE INDEX index_name ON table_name (field_name);Primary Key Index
ALTER TABLE table_name ADD PRIMARY KEY (field_name);Full-text Index
CREATE FULLTEXT INDEX index_name ON table_name (field_name);Physical Division
Clustered Index
The index and data of the clustered index are stored together, and the order of the index is consistent with the physical storage order of the data. In MySQL, the primary key index is a clustered index, and the index and data are both in the same .ibd file.
Advantages and Disadvantages of Clustered Index
Advantages:
- The clustered index can reduce disk I/O operations and improve query efficiency. Once the index is queried, the data is found, and there is no need to query the data again.
- The clustered index can reduce data fragments and improve data storage efficiency.
Disadvantages:
- The maintenance cost of the clustered index is high, and the index needs to be maintained when inserting, deleting, and updating data.
- The data storage of the clustered index is ordered. If the inserted data is unordered, it may cause the data storage to be discontinuous and increase the data storage space.
Non-clustered Index
The index and data of the non-clustered index are stored in different places, and the order of the index is inconsistent with the physical storage order of the data. In MySQL, the ordinary index is a non-clustered index, and the index and data are stored in two .ibd files separately.
Advantages and Disadvantages of Non-clustered Index
Advantages:
- The maintenance cost of the non-clustered index is low, and only the index needs to be maintained when inserting, deleting, and updating data.
- The data storage of the non-clustered index is unordered. When inserting data, it will not cause the data storage to be discontinuous, reducing the data storage space.
Disadvantages:
- The query efficiency of the non-clustered index is low. After querying the index, you need to query the data again.
- The non-clustered index will increase disk I/O operations and reduce query efficiency.
- The non-clustered index will increase data fragments and reduce data storage efficiency.
- The data storage of the non-clustered index is unordered, which may cause the data storage to be discontinuous and increase the data storage space.
Covering Index
Since the non-clustered index and the data are stored separately, it means that after using the index to search for the data, you need to go back to the table to query the data, which will increase an I/O operation. To reduce I/O operations, you can use a covering index. A covering index refers to the fact that all the fields queried are in the index, and there is no need to go back to the table to query the data.
Field Number Division
Single Column Index
CREATE INDEX index_name ON table_name (field_name);Composite Index
CREATE INDEX index_name ON table_name (field_name1, field_name2, ...);Translate to English:
Principles for Creating Indexes
- Most Left Prefix Principle
MySQL indexes use the most left prefix principle, that is, only the most left prefix column of the index can be used in the query. For example, if a composite index (a, b, c) is created, then you can use (a), (a, b), (a, b, c) three indexes in the query, but you cannot use (b, c), (c) and other indexes.
Warning
The most left match principle can trigger index query when encountering >=, <=, between, like prefix match, but if it encounters > and <, it will not trigger index query.
- Choose Unique Index
When choosing an index, you should prefer to choose a unique index, because the unique index can guarantee the uniqueness of the data and avoid data duplication.
- Choose High Discrimination Index
When choosing an index, you should choose a high discrimination index. The high discrimination index can reduce the amount of data scanned and improve query efficiency.
- Choose Index Column
When choosing an index column, you should choose a frequently queried column, avoid choosing infrequently used columns, and improve the utilization rate of the index.
Recommended Fields to Choose
- Frequently queried fields
- Frequently sorted fields
- Fields that are not NULL
- Fields often used for JOIN
- Try to Use Prefix Index
If the length of the index field is long, you can use a prefix index. The prefix index can reduce the storage space of the index and improve the query efficiency of the index.
- Try to Extend Index Instead of Creating New Index
If we already have an a index, if we need an a,b index, then we can directly extend the b field on the a index, instead of creating a new a,b index.
- Don't Have Too Many Indexes
The number of indexes in a single table should not be too many. Too many indexes will increase the maintenance cost of the data and reduce the data write efficiency.
Index Pushdown
Index pushdown (Index Condition Pushdown) is an optimization feature introduced in MySQL 5.6, which can reduce the back-table query data and improve query efficiency, mainly used for composite indexes.
Working Principle
Before there was no index pushdown, if we had a composite index (a, b), the query condition was a = 1 and b = 2, MySQL would first use the index (a, b) to query all a = 1 data, and then go back to the table to query the corresponding complete data row, and then use the b = 2 condition to judge whether each row meets the condition, and return the data rows that meet the condition.
With index pushdown, MySQL will first use the index (a, b) to query all a = 1 and b = 2 data, and then go back to the table to query the corresponding complete data row, reducing the amount of back-table query data and improving query efficiency.
Data Structure of Indexes
B-Tree
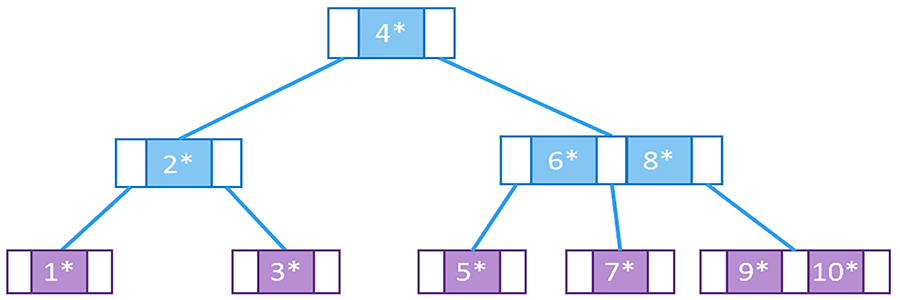
A B-tree is a type of multi-way balanced search tree and is a commonly used index data structure.
Characteristics of B-Tree:
- Each node contains multiple child nodes, and the number of child nodes for each node ranges from
[m/2, m], wheremis the number of layers in the B-tree. - All leaf nodes are on the same level.
- The root node has at least two child nodes unless the root node is a leaf node.
- A non-leaf node with
kchild nodes containsk-1key values. - Each node contains both the index and all data.
B+ Tree
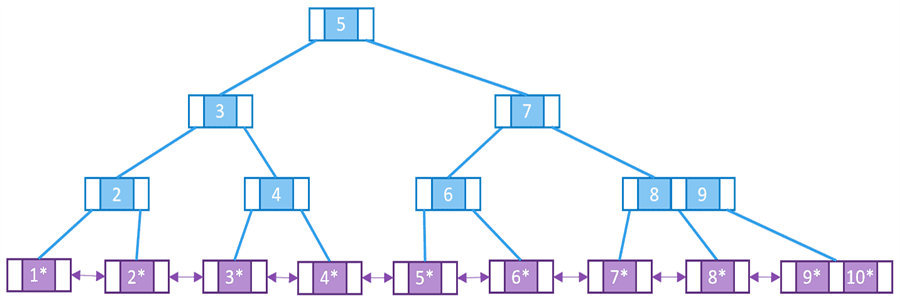
A B+ tree is a variant of the B-tree and is a commonly used index data structure. Compared with the B-tree, the leaf nodes of the B+ tree only contain indexes, not data, all leaf nodes are on the same level, and leaf nodes are connected by pointers. Since the node only contains the index, under the same block size, the B+ tree can store more indexes, reduce the number of layers of the tree, and improve the query efficiency. Since the leaf nodes are connected by pointers, it can support range queries, and the query speed is much faster than the B-tree.
Characteristics of B+ Tree:
- All leaf nodes are on the same level.
- Non-leaf nodes only contain indexes, not data.
- Leaf nodes are connected by pointers.
- Leaf nodes contain all data.
- For the same amount of data, the height of the B+ tree is lower than the B-tree.
Differences between B-Tree and B+ Tree
| B-Tree | B+ Tree | |
|---|---|---|
| Data Pointers and Keys | All internal nodes and leaf nodes contain data pointers and keys | Only leaf nodes contain data pointers and keys, internal nodes only contain keys |
| Duplicate Keys | There are no duplicate keys | Duplicate keys exist, all internal nodes also exist in the leaves |
| Leaf Node Linking | Leaf nodes are not linked to each other | Leaf nodes are linked to each other |
| Sequential Access | Sequential access of nodes is not possible, range queries require in-order traversal | All nodes exist in the leaves, so they can be accessed sequentially like a linked list |
| Search Speed | The speed of searching keys is slower | The search speed is faster |
| Height for Specific Number of Entries | For a specific number of entries, the height of the B-Tree is larger | For the same number of entries, the height of the B+ Tree is less than the B-Tree |